Подсистемы хранения данных

|
Какие задачи надо решить проектировщику в процессе создания системы хранения данных?
В процессе создания СХД необходимо достичь оптимального соотношения производительности, доступности (надежного хранения и отказоустойчивого доступа) и совокупной стоимости владения.
Одним из наиболее часто используемых методов обеспечения высокой доступности СХД является дублирование, которое повышает стоимость системы. Если не учитывать бизнес-требований заказчика к доступности системы, то система становится неоправданно дорогой. Погоня за ненужной производительностью также приведет к использованию дорогих технических средств. Помимо высоких показателей производительности, доступности и низкой стоимости нужно также обеспечить требуемую функциональность — объем хранения и число подключаемых серверов.
К сожалению, заказчики не всегда могут описать требования по производительности в количественных характеристиках, принятых для систем хранения — пропускной способности (Мбайт/с) или производительности (операций ввода-вывода в секунду — I/O per second (IOPS)). Поэтому, чтобы определить если не количественные характеристики, то хотя бы характер нагрузки, проектировщику необходимо выяснить, работу каких приложений должна обеспечивать СХД.
Различные классы приложений создают разную нагрузку на дисковую подсистему. Например, для СУБД характерны виды нагрузок, зависящие от классов задач — транзакционные системы (Online Transaction Processing (OLTP)) и аналитические системы (Decision Support Systems (DSS)). Для задач класса OLTP характерным является большой поток запросов на ввод-вывод небольших порций данных. Для задач класса DSS, напротив, характерно небольшое число запросов на чтение больших порций информации.
От того, какую нагрузку дает приложение, зависит выбор способа распределения данных по дискам и определение объема кэш-памяти дискового массива. Так для OLTP-задач наличие кэш-памяти в дисковом массиве может сыграть существенную роль для повышения производительности ввода-вывода. Напротив, в задачах класса DSS происходит считывание больших объемов данных, что практически исключает их повторное попадание в кэш-память (в отличие от OLTP-задач).
Таким образом, кеширование считываемых данных при обработке DSS-задач не всегда увеличивает их производительность.
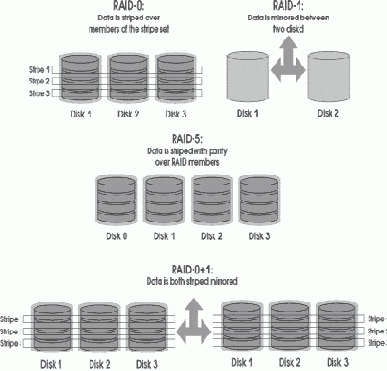
Рисунок 3. Уровни RAID
К типам нагрузки на СХД, производимыми задачами класса OLTP, DSS и файловыми сервисами можно отнести другие известные типы приложений. Так, почтовый сервис, построенный на базе MS Exchange или Lotus Domino, даёт сходную нагрузку на СХД, что и OLTP, поскольку указанные продукты построены на базе СУБД. Почтовый же сервис, основанный на sendmail, производит нагрузку на СХД, характерную для файловой системы с частым изменением метаданных. Средства резервного копирования выполняют последовательное чтение данных, подлежащих резервному копированию, что делает характер их операций схожим с DSS-задачами.
Существует еще один, не упомянутый ранее, тип нагрузки, характерный для процессов журналирования. Примером могут служить записи журналов транзакций СУБД или журналов событий операционных систем. К этому классу также можно отнести задачи загрузки данных в БД или хранилище данных (Data Warehouse). Нагрузка, осуществляемая на СХД этим классом задач, аналогична нагрузке DSS только для операций записи. Здесь наличие кэш-памяти (на запись) в дисковом массиве не увеличивает производительности записи данных. Данный тезис необходимо пояснить. Обычно применение кэш-памяти на запись уменьшает время, которое сервер тратит на операцию записи и ожидание её завершения. Но при записи большого объема информации (загрузка данных в БД) или при записи данных, которые пишутся на новое место, таких как журнал транзакций, существует высокая вероятность возникновения ситуации, когда кэш-память на запись уже будет полностью занята, а новый записываемый блок не соответствует ни одному из уже присутствующих в кэш-памяти. В этом случае массиву придется освободить несколько блоков кэш-памяти, записав их содержимое на диски, прежде чем начать обработку поступившей операции.
Определить классы задач, которые будет обслуживать СХД, необходимо не только для выработки политики работы с кэш, но также для распределения данных по дискам (disk layout).
Для обеспечения надежного хранения информации диски организуются в уровни RAID 1, 0+1/1+0 или 5. Самым экономичным с точки зрения использования дополнительного (дублирующего) дискового пространства является уровень RAID 5. Однако производительность RAID 5 ниже, чем у RAID 1 или 0+1 при частых случайных изменениях данных, характерных для OLTP-задач, и высока при считывании данных, что характерно для DSS-задач.
Также разные уровни RAID обеспечивают различные уровни отказоустойчивости дисковой памяти к сбоям отдельных дисков. Так RAID 5 не спасает от двух последовательных отказов дисков, впрочем, как и RAID 0+1, если это диски разных половин "зеркала". Наиболее отказоустойчивым является уровень RAID 1+0 (попарное "зеркалирование" дисков и затем их "striping(1)"), поэтому его рекомендуется применять для хранения критичных данных, например, журналов транзакций СУБД. Практика показывает, что для хранения файловых систем и данных DSS-задач достаточно использовать RAID 5. Однако, если файловая система часто изменяется как, например, в почтовых системах sendmail, то имеет смысл использовать журналированную файловую систему или файловую систему с отдельно хранимыми метаданными, например файловую систему Sun QFS. Тогда для хранения журналов или отдельных метаданных лучше применять RAID 1 или 1+0.
(1) Striping — метод размещения данных на дисках, при котором последовательно идущие блоки данных, составляющие логический том, записываются поочередно на каждый физический диск, входящий в дисковую группу. Таким образом достигается большая производительность, поскольку операции чтения и записи на диски могут производиться параллельно по сравнению с вариантом, когда все блоки логического тома записывается на один диск. Подробнее о striping и его влиянии на производительность ввода-вывода можно прочитать в [3].
Подробнее о влиянии кэш-памяти и disk layout на производительность ввода-вывода задач класса OLTP и DSS можно прочитать в [3].
Для "больших" систем актуальной становится оптимизация настроек СХД, направленная на повышение быстродействия для достижения заданного уровня сервиса.
Под "большой" понимается такая система, в которой обрабатывается значительный объем данных — единицы и десятки терабайт, и/или к СХД подключены десятки серверов. Для небольших систем проблемы с быстродействием можно решить применением более производительной аппаратуры. В "больших" системах такой подход может оказаться неприемлемым либо в связи с тем, что потребуется очень дорогая аппаратура, либо в связи с тем, что уже достигнут предел аппаратной производительности. Единственным решением в данном случае является оптимизация. Для оптимизации производительности СХД желательно иметь возможность управлять настройками на всем пути следования данных от процессора к дискам и обратно. Для СУБД ORACLE такая оптимизация заключается в возможности использовать KAIO, а также возможности отключить кэш файловой системы для файлов данных ORACLE (поскольку СУБД ORACLE кэширует данные в собственной области памяти SGA). Для этой цели можно использовать упомянутый ранее пакет VERITAS DBE. Если в системе эксплуатируются OLTP- и DSS-задачи (что является типичным для большинства систем), то для оптимизации производительности дискового массива желательно иметь возможность управлять настройками кэш-памяти для каждого логического диска (LUN) в отдельности. Это необходимо для того, чтобы для тех дисков, где расположены данные OLTP-задачи, использовать кэш (и желательно большого объема), а для дисков с данными DSS-задачи использование кэш-памяти отключить. Однако, если для OLTP- и DSS-задач используются одни и те же таблицы данных, то такие настройки теряют смысл до тех пор, пока не будет решен вопрос о физическом разнесении данных задач по разным дискам, а выполнение самих задач перенесено на разные серверы. Это можно реализовать средствами СУБД, например, с помощью экспорта данных в файл и импорта их в другую базу. Если объем данных велик и синхронизацию баз данных OLTP- и DSS-задач надо проводить достаточно часто, этот вариант может оказаться неэффективным. Здесь может помочь технология создания PIT-копий данных, реализованная в большинстве современных дисковых массивов.
Выше говорилось, что СХД является важным звеном в обеспечении заданного уровня сервисов, предоставляемых информационной системой. Уровень сервиса зависит не только от производительности СХД, вопросы обеспечения которой только что обсуждались, но также от готовности и надежного хранения данных, другими словами, от доступности СХД. Исходя из бизнес-требований к информационной системе, необходимо определить режимы её работы (24х7, 12х5 и т.п.), степень критичности данных в зависимости от степени критичности сервисов, использующих эти данные, требования к готовности и надежности данных в зависимости от степени их критичности и режимов работы системы.
Рассмотрим для примера работу информационной системы коммерческого банка. В банке эксплуатируется Автоматизированная Банковская Система (АБС), обслуживающая финансовые транзакции клиентов банка (OLTP-задача). Режим работы банка 8:00-20:00. Банк имеет несколько филиалов в ряде регионов России, которые работают с АБС головного офиса в терминальном режиме. Рабочие часы АБС составляют 6:00-22:00. Допустимое время простоя АБС — не более 1 часа. Допустимо потерять данные АБС не более чем за 0,5 часа, поскольку за этот период они могут быть повторно введены в систему с бумажных носителей (фактически это обусловлено бизнес-требованием по времени прохождения финансовой транзакции). Также в банке эксплуатируются аналитические задачи (DSS) на основе данных из АБС. Рабочее время аналитиков 9:00-18:00. Допустимое время простоя сервисов аналитических задач не более 4-х часов. Загрузка данных из АБС в аналитическую базу (синхронизация) происходит по закрытии "опердня" в 23:00. Таким образом, отставание аналитических данных от АБС составляет текущий "опердень". В случае потери данных аналитических задач они должны быть восстановлены на момент последнего закрытого "опердня". Срок восстановления аналитических данных зависит от того, в какой момент случился сбой в системе. Если сбой произошел утром, то аналитические данные должны быть восстановлены не позднее, чем за 4 часа.
Если сбой случился после обеда или вечером, то восстановление должно быть завершено к утру следующего дня, плюс в аналитическую базу должны быть загружены данные последнего "опердня". Для выполнения OLTP- и DSS-задач используется СУБД ORACLE 8i.
Анализируя бизнес-требования к информационной системе из приведенного примера, получается, что СХД банка должна обеспечивать работу двух типов задач — OLTP и DSS. Данные OLTP-задачи являются критичными для системы в период с 6:00 до 23:00 (учитывается загрузка данных из АБС в аналитическую базу) и должны обеспечивать высокую готовность (простой не более 1 часа). Требования по надежности также высоки — потери не более получаса работы. Напротив, данные DSS-задачи не столь критичны и требования по готовности не столь высоки, но должна быть обеспечена высокая надежность — потери не допустимы.
В предыдущем разделе были указаны методы обеспечения доступности СХД: дублирование аппаратных компонентов и дублирование данных, включающее применение различных уровней RAID, резервное копирование и репликацию в резервный центр.
В приведенном примере ИС банка можно рекомендовать использовать RAID 1+0 для файлов данных и журналов транзакций OLTP-задачи, при этом необходимо расположить файлы данных и журналы транзакций на разных LUN. Такая схема позволит управлять производительностью (если используемый массив может управлять кэш-памятью для отдельных LUN) и обеспечит высокую надежность хранения данных. Для данных DSS-задачи рекомендуется использовать RAID 5. Этого вполне достаточно для надежного хранения данных DSS-задачи и производительности при чтении данных. Для отказоустойчивого доступа к данным в серверах АБС необходимо установить как минимум по 2 FC-НВА и подключить их к разным контроллерам дискового массива. При этом компоненты дискового массива должны быть продублированы, а участки кэш-памяти, используемые для операций записи, зазеркалированы и защищены от сбоев питания.
О выборе массива определенного класса и с определенными характеристиками речь пойдет в следующем разделе.
Но необходимо отметить, что не обязательно все компоненты массива должны быть дублированы, если за указанный допустимый период простоя они могут быть заменены, а данные при необходимости восстановлены с резервных копий.
Тип приложения влияет на то, как будет осуществляться резервное копирование. Например, для резервного копирования СУБД ORACLE средствами Recovery Manager (RMAN) рекомендуется использовать отдельный сервер (а, следовательно, и отдельный экземпляр базы данных и дисковое пространство для него), где будет размещен RMAN Recovery Catalog. Для резервного копирования файловых систем этого не требуется. Чтобы восстановить базу данных ORACLE необходимо иметь копии журналов транзакций, для чего рекомендуется активизировать в СУБД ORACLE режим архивирования журналов транзакций (ARCHIVELOG). Для архива журналов транзакций потребуется выделить дисковое пространство. Для его защиты от разрушения уровня RAID 5 будет достаточно. Какой тип резервного копирования использовать (полное или инкрементальное) зависит от того, за какое время можно будет скопировать базу данных и журналы транзакций с лент на диски, и укладывается ли полное резервное копирование в отведенное временное окно. Использование полного ежедневного резервного копирования позволяет восстановить базу быстрее, чем, например, применение полного еженедельного и каждодневного инкрементального. При расчете времени восстановления СУБД ORACLE рекомендуется учесть, что данные c ленты копируются на диски медленнее, чем записываются с дисков на ленты, поскольку надо записывать метаданные файловой системы [2]. Также надо учесть, что после копирования файлов данных и журналов транзакций с лент на диски СУБД ORACLE должна будет выполнить процедуру восстановления базы — RECOVERY, т.е. "накатить" все незавершенные транзакции из журналов.
В приведенном примере ИС банка журналы транзакций необходимо будет копировать каждые полчаса. Если изменения в базе данных АБС не велики (за день осуществляется небольшое число финансовых транзакций), то процедура RECOVERY будет выполняться быстро (не более десятка минут).
Если база данных и журналы транзакций могут быть скопированы с лент на диски менее чем за 50 минут, достаточно будет производить полное резервное копирование базы раз в сутки после закрытия "опердня". Но если эти условия не выполняются, то потребуется использовать более сложные технологии, такие как Storage Checkpoint, реализованные в VERITAS DBE, или средства создания PIT-копий.
Как говориться, сбой сбою рознь. До этого момента обсуждались методы восстановления данных после "незначительных" сбоев — разрушения данных в результате отказов отдельных элементов аппаратуры (дисков, контроллеров и т.п.), ошибок ПО или действий персонала/пользователей системы. Сбой в работе системы может произойти из-за аварии, причиной которой может быть выход из стоя технического средства целиком (дискового массива или сервера) или, что еще хуже, техногенная (пожар, затопление) или природная (землетрясение, наводнение) катастрофа. От того, какие требования предъявляются к СХД по срокам восстановления после аварий, применяются различные схемы резервирования данных, что влияет на выбор технических и программных средств и, в конечном итоге, на стоимость решения.
В примере с ИС банка, если требуется обеспечить восстановление работоспособности АБС в течение 1 часа после техногенной катастрофы (например, пожара) в помещении комплекса, то, в резервном центре необходимо помимо серверов иметь резервный дисковый массив, дубликаты лент с резервными копиями и ленточную библиотеку достаточной мощности. Если объемы данных АБС и интенсивность их изменений не велики, то постоянное резервное копирование и регулярная перевозка дубликатов лент в резервный центр будет достаточным для защиты данных от аварии. Но в случае больших объемов данных (сотни гигабайт) и частых изменениях в базе (большом числе финансовых транзакций) указанная схема не эффективна, особенно, если учитывать, что резервное копирование дает существенную дополнительную нагрузку на аппаратный комплекс и, следовательно, может привести к недопустимому снижению его производительности.
Альтернативным решением в приведенном примере может служить передача данных между массивами, расположенными на разных площадках, которая реализуется с помощью репликации или зеркалирования.
Репликация может выполняться программным обеспечением, установленным на серверах (программная репликация), или встроенным в дисковые массивы программным обеспечением "прозрачно" для серверов (аппаратная репликация). Для организации репликации или зеркалирования необходимо создать высокопроизводительную инфраструктуру передачи данных, объединяющую обе площадки. Как правило, для этого применяют SAN [1].
При разработке проекта СХД для сохранения вложенных инвестиций необходимо учесть имеющиеся технические средства и наиболее оптимальным образом вписать их в новую систему. Надо также учесть наличие, навыки и опыт обслуживающего персонала. Если квалификации персонала недостаточно для обслуживания высокотехнологичной системы, то помимо организации обучения, тщательной проработки регламентов составления детальных инструкций и другой рабочей документации, необходимо внедрить систему управления СХД. Система управления не только облегчит работу, но еще и снизит вероятность ошибочных действий персонала, которые могут привести к потере данных.
Не секрет, что наличие плана развития системы облегчает её внедрение и снижает расходы на модернизацию, по сравнению с хаотичным развитием. С другой стороны, бизнес подвержен изменениям — меняются задачи, появляются новые пользователи и т.п. Поэтому, даже хорошо спроектированная СХД со временем перестает удовлетворять бизнес-требованиям.
Помочь в решении указных проблем может опять же внедрение все той же системы управления, которая позволит отследить изменение нагрузок на систему хранения, учесть утилизацию дискового пространства, спрогнозировать потребности в его наращивании и т.д.
Суммируя выше сказанное получаем, что для определения требуемых параметров СХД и поддержания их в заданных рамках необходимо четко определить классы, режимы работы и характеристики задач, работу которых должна обеспечить СХД, требуемый объем хранения данных и его возможный прирост, количество и платформы (UNIX, Windows и др.) подключаемых серверов.Иными словами, при создании СХД проектировщик должен исходить от задач и бизнес-требований заказчика.